사내에서 사용하는 어드민(이하 어드민 A)/외부에서 사용하는 어드민(이하 어드민 B)이 사망하는 사례가 속출하였다. 그 시점은 내가 새롭게 서버를 옮긴 이후부터 발생했다. 내가 서버를 옮긴 것과 이 일이 관련이 없다고 생각했지만, 우선 내가 서버를 옮긴 이후에 발생한 사건이기도 해서 부검을 통해 사인을 밝혀내는 게 우선이었다.
왜 사망했나
1 2 3
org.springframework.dao.QueryTimeoutException: Redis command timed out; nested exception is com.lambdaworks.redis.RedisCommandTimeoutException: Command timed out at org.springframework.data.redis.connection.lettuce.LettuceExceptionConverter.convert(LettuceExceptionConverter.java:66) at org.springframework.data.redis.connection.lettuce.LettuceExceptionConverter.convert(LettuceExceptionConverter.java:41)
이 글은 이일웅 님께서 번역하신 자바 최적화란 책을 읽던 도중 공부한 내용을 정리한 글입니다. 절대 해당 책의 홍보는 아니며 좋은 책을 써준 사람과 번역해주신 분께 진심으로 감사하는 마음에 썼습니다. 이 글을 읽어보시기 전에 Garbage Collection Basic 편을 읽어보시면 더 도움이 될 것입니다 :)
그림을 그리다보니 Stack에 있는 동그라미 모양과 힙 메모리에 있는 동그라미 모양이 동일한 그림들이 많이 있습니다. 이건 둘이 동일한 메모리를 의미하는 게 아니라 그냥 스택에서 힙을 참조한다는 걸 그린 건데, 사실 둘의 모양을 다르게 그려야하는데 아무 생각없이 복붙해서 그리다보니 이렇게 그리게 되었고… 되돌리기에는 너무 많이 그림을 그려놔서(히스토리 추적이 안 되게 막 그려서…) 귀챠니즘으로 인해 그림을 수정하지 않았습니다. 이 점 참고하셔서 보시길 바랍니다!
Spring Data JPA를 이용하다보면 종종 org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags이란 메세지를 보게 된다. 우선 어떤 상황에 나타나는지 한 번 살펴보자.
엄마가 있고, 아들/딸들이 있는데 아들/딸들을 EAGER로 fetch해 올 때 발생한다. (즉, OneToMany, ManyToMany인 Bag 두 개 이상을 EAGER로 fetch할 때 발생한다.) EAGER로 땡겨오면 N+1 쿼리 문제가 존재하기 때문에 fetchType을 전부 LAZY로 바꾼 후 한 방 쿼리로 불러와도 문제는 재발한다.
우선 테스트를 돌릴 때마다 DB를 초기화했다. (인메모리 DB인 H2를 사용했다.) 따라서 테스트 할 데이터를 setup 메서드를 통해 데이터를 DB에 밀어넣고 있었다. 그리고 테스트 케이스에서 해당 엔터티를 불러오는 간단한 코드인데 나는 select 쿼리가 날아갈 줄 알았다. 하지만 insert 쿼리만 날아가고, 이거 가지고 코드를 이리저리 바꿔보며 온갖 삽질을 한 것 같다.
왜 select 쿼리가 찍히지 않을까… 한 2시간 가까이를 이거 때문에 계속 삽질하고 있었다. 그리고 스프링 관련 커뮤니티에 질문하려고 아마 SomeEntity 엔터티가 생성되면서 ID 값이 어딘가에 저장돼서 동일한...까지 딱 치고 있는데 어딘가 저장에 딱 꽂혀서 아! 맞다! 하고 그동안 JPA를 안 쓴 지 오래돼서 까먹었구나… 하고 한참동안 너무 허무했었다.
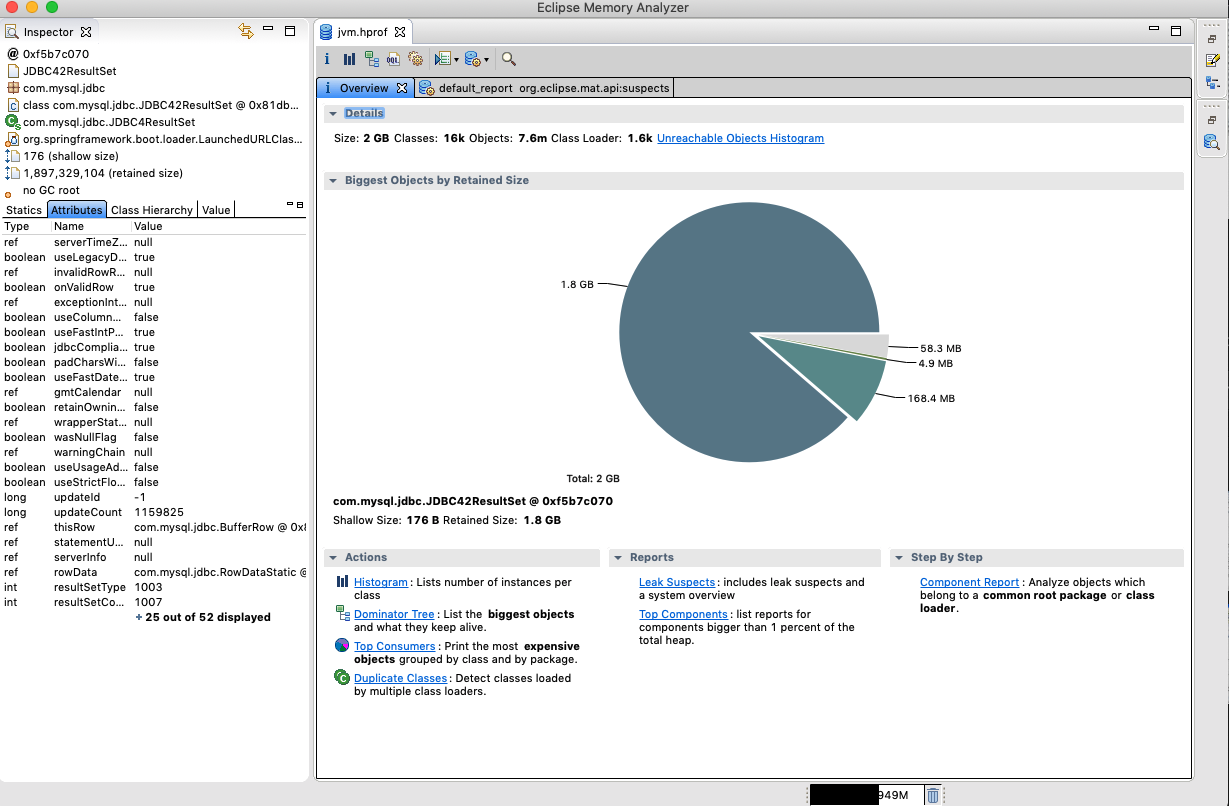
어느 날 서비스가 갑자기 다운되는 사례가 발생했다. 다행히 서버를 이중화시켜놓아서 장애가 발생하진 않았지만 그래도 왜 다운된 건지 원인 분석을 해야했다. 나의 실수로 인해 WAS 로그는 제대로 남겨져있지 않았고, CTO 님께서 힙 덤프 같은 거라도 떠져있나 보라고 하셔서 지푸라기라도 잪는 심정으로 기대를 했는데 희망을 저버리지 않았다.
위 옵션으로 인해 OOME(Out of Memory Exception) 발생 시 힙 덤프를 뜨게 해놓았는데 다행히 힙 덤프가 존재했다.
여기서 힙 덤프는 힙 메모리의 내용을 그대로 떠놓은 파일이다. 따라서 힙 메모리에 어떤 객체들로 가득 채워져있었는지 분석할 수 있게 되었다. 여기서 흥분해서 서버에서 vi 등등을 이용해 힙 덤프 파일을 열면 안 된다. (용량이 큰 로그 및 다른 파일도 물론 서버에서 절대 열면 안 된다.) 여는 순간 힙 메모리 사이즈만큼 서버의 메모리를 사용하게 돼서 서버가 다운될 수도 있다. 무조건 scp 등등의 명령어를 통해 로컬로 복사한 후에 열어보는 습관을 가지자.
LB에 바로 도메인을 붙여도 되지만 롤백을 최대한 빨리하기 위해 기존 서버에서 LB로 업스트림 걸어놓았다.
만약 새로운 서버에서 문제가 생겼다고 가정
이 때 LB에 바로 도메인을 달아놓았다면… 2-1. 기존의 서버로 다시 도메인 변경 2-2. DNS 캐시가 날아갈 때까지 유저에게 장애 발생 2-3. 클라이언트의 설정에 따라서 DNS 캐시가 언제 날아갈지 모르는 상황… (과연 일반 유저들이 브라우저의 DNS 캐시 지우는 방법을 알고 있을까?)
이 때 기존 서버는 내비두고 LB로 업스트림을 걸어놓았다면… 3-1. 기존 로컬 서버를 업스트림 서버로 변경 3-2. nginx -s reload 3-3. 수 초 이내로 원래 서버로 원복


")







")