(JPA) persist vs merge
들어가기에 앞서
글을 정리하다 보니 너무 깊게 파고 정리한 거 같아 글이 너무 길어져서 아무도 읽지 않을 것 같아 정리부터 해보겠습니다.
- 엔티티 매니저의 persist 메서드는 리턴값이 없기 때문에 원본 객체를 수정하고, merge 메서드는 리턴값이 있기 때문에 새로운 객체를 반환합니다.
- JpaRepository.save 호출 시 엔티티의 식별자(@Id, @EmbeddedId 어노테이션이 붙은 컬럼 등등)가 붙은 필드의 타입이 primitive type이 아닐 때는 null이거나 숫자형일 때는 0이면 새로운 엔티티라고 판단하면서 persist 메서드가 호출되고, 그게 아니면 merge 메서드가 호출됩니다.
- JPQL 호출 시 FlushMode가 AUTO(하이버네이트 기본 FlushMode)라 하더라도 쿼리 지연 저장소에 JPQL에서 사용하는 테이블과 관련있는 쿼리가 저장돼있지 않다면 flush를 호출하지 않습니다.
- JPQL 호출 시 AutoFlushEvent가 발생하면서 flush 이전에 cascade가 먼저 이뤄지는데 이 때는 PersistEvent가 발생하면서 원본 엔티티를 변경합니다.
- JpaRepository.save 호출 시 엔티티가 새로운 엔티티가 아니면 MergeEvent가 발생하고, cascade가 발생하는데 이 때 해당 엔티티에 대해 MergeEvent가 또 발생하면서 Transient 상태인 경우에는 원본 엔티티를 카피하고 카피한 객체의 값을 수정하고 연관관계가 맺어진 엔티티에서는 레퍼런스도 카피 객체로 바꿔치기 하고 있습니다.
- JpaRepository.save 호출 시 엔티티가 새로운 엔티티가 아니면 MergeEvent가 발생하는데 cascade 이후에 DirtyChecking이나 Flush가 호출되지 않습니다.
- 모든 트랜잭션이 끝난 이후에 커밋 이전에 FlushMode가 MANUAL이 아니고, Managed Entity가 존재하면 FlushEvent를 발생시켜서 DirtyChecking 및 Flush를 하게 됩니다.
제목은 엔티티 매니저의 persist와 merge에 대해 개념을 설명할 것처럼 적어놨지만 이해를 돕기 위해, 흥미 유발을 위해 사내에서 겪었던 문제 과정을 서술하겠습니다.
문제 상황
1 |
|
자식을 낳는 Mother 엔티티와 Child 엔티티가 1:N 양방향 관계 매핑이 돼있는 상황입니다.
그리고 Mother의 모든 Cascade(영속성 전이) Action에 대해 children에게 전파가 되도록 하였습니다.
이제 산모는 출산 예정일이 다가와 산부인과에서 출산을 시작합니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43// 산부인과 표현이 이게 맞는지 모르겠네용~
class ObGyn(
private val motherRepository: MotherRepository,
// 산부인과에서 영재 양성 기관과 호적 저장소를 알고 있는 기이한 현상이지만 예제를 위해서 참아주세요!
private val talentedPersonTrainingSchool: TalentedPersonTrainingSchool,
private val familyRegisterRepository: FamilyRegisterRepository
) {
// @Transactional 어노테이션을 붙인 이유는 예제를 위해 영속성 컨텍스트를 강제로 넓히기 위함이지 다른 이유는 없습니다.
fun naturalDeliveryWith(father: Father) {
val mother =
motherRepository.findByIdOrNull(father.wifeId) ?: throw MotherNotFoundException("병원에 산모가 없습니다.")
val child = Child.create(father, mother)
// 엄마가 아이를 낳습니다.
mother.born(child)
// 아이의 부모는 아이가 태어나자마자 영재라는 삘이 와서 바로 영재 양성 기관에 등록합니다.
talentedPersonTrainingSchool.register(child)
// 아이가 너무 마음에 들어 바로 호적에 올려버립니다.
val familyRegister = familyRegisterRepository.findByFatherId(father.id)
familyRegister?.add(child)
if (familyRegister != null) {
familyRegisterRepository.save(familyRegister)
}
// 산모의 최근 출산일도 변경되었고, 자식도 새롭게 생성되어서 child도 같이 저장해야할 것 같지만
// 산모 객체의 children 필드는 CascadeType이 ALL이기 때문에 따로 child 객체는 저장하지 않아도 됩니다.
motherRepository.save(mother)
}
}
class TalentedPersonTrainingSchool(
private val talentedPersonRepository: TalentedPersonRepository
) {
fun register(child: Child) {
val talentedPerson = TalentedPerson(child.id)
talentedPersonRepository.save(talentedPerson)
}
}
코드가 더럽긴 하지만, 일단 코드는 잘 돌아갈 것 같습니다만…
TalentedPersonTrainingSchool의 register 메서드를 호출할 때 TalentedPerson 객체에 child.id 필드에 접근합니다.
 상태라 id는 null입니다.")

save를 하기 전에 엔티티의 ID를 사용하려고 해서 문제가 발생했으니 이제 save를 먼저 호출하면 될 것 같습니다.1
2
3
4
5
6
7
8
9
10
11
fun naturalDeliveryWith(father: Father) {
// ...
// child 엔티티의 id를 사용하기 전에 먼저 save를 때려줍니다.
motherRepository.save(mother)
talentedPersonTrainingSchool.register(child)
// ...
}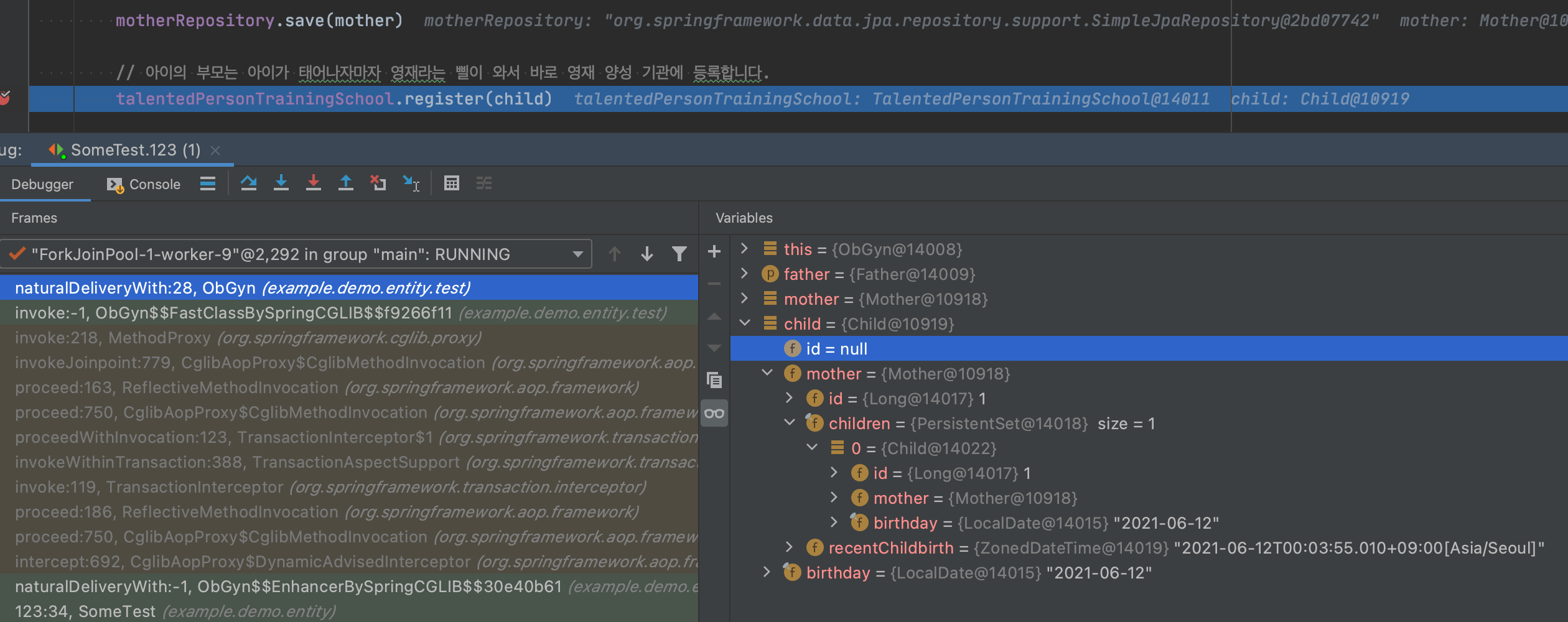
save를 먼저 호출했음에도 불구하고, child의 id가 null입니다.
하지만 mother.children[0]에 있는 child에는 id가 박혀있습니다!!
또한 child와 mother.children[0]의 레퍼런스가 다른 걸 보아 다른 객체로 보이는군요!!
JPA 알못인 저에게는 정말 이해할 수 없는 미스테리였습니다.
원인 분석
먼저 쿼리 로그를 한 번 봐봅시다.
save를 가장 나중에 호출한 케이스입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49// motherRepository.findByIdOrNull(father.wifeId)
Hibernate:
select
mother0_.id as id1_4_0_,
mother0_.recent_childbirth as recent_c2_4_0_
from
mother mother0_
where
mother0_.id=?
// mother.children의 FetchType이 eager가 아니기 때문에 실제 children을 사용할 때(mother.born(child) 메서드 안에서) lazy하게 쿼리를 날립니다.
Hibernate:
select
children0_.mother_id as mother_i3_2_0_,
children0_.id as id1_2_0_,
children0_.id as id1_2_1_,
children0_.birthday as birthday2_2_1_,
children0_.mother_id as mother_i3_2_1_
from
child children0_
where
children0_.mother_id=?
// familyRegisterRepository.findByFatherId(father.id)는 JPQL이기 때문에 쿼리 실행 이전에 flush를 호출(hibernate의 기본 FlushMode가 AUTO이상이고 기타 등등의 사유로 인해) 해야하는지 판단하는데
// mother.born(child)에 의해 mother(Managed Entity)의 children의 child(Transient Entity)에 대해서는 insert 쿼리가 날아갔습니다.
// 신기한 건 mother(Managed Entity)는 변경사항(recentChildbirth 필드)이 있는데도 update 쿼리가 실행되지 않았습니다.
Hibernate:
insert
into
child
(id, birthday, mother_id)
values
(null, ?, ?)
// familyRegisterRepository.findByFatherId(father.id)
Hibernate:
select
familyregi0_.id as id1_3_,
familyregi0_.fatherId as fatherid2_3_,
familyregi0_.motherId as motherid3_3_
from
family_register familyregi0_
where
familyregi0_.fatherId=?
// motherRepository.save(mother) 이후에 바로 호출된 게 아니라 naturalDeliveryWith 메서드를 마치고 TransactionInterceptor에서 커밋하기 전에 flush를 호출했습니다.
Hibernate:
update
mother
set
recent_childbirth=?
where
id=?
Child는 왜 insert 됐는가??
너무 내용이 길어서 3 줄로 요약해보면
- JPQL 호출 이전에 AutoFlushEvent를 발생시키고 이벤트 핸들러인 DefaultAutoFlushEventListener 안에서 flushMightBeNeeded 메서드를 호출하는데 하이버네이트의 기본 FlushMode가 AUTO이기 때문에 true를 반환합니다.
- 본격적으로 flush 호출 이전에 전처리 작업(AbstractFlushingEventListener 클래스의 prepareEntityFlushes 메서드 등등)에서 영속성 컨텍스트에 있는 엔티티들에 대해 cascade를 수행합니다.
- 이 때 영속성 컨텍스트에 있는 Mother 엔티티의 children 프로퍼티에 대해 cascade 되면서 insert 쿼리가 호출됐습니다.
child가 insert 된 이유는 flush를 호출했기 때문이 아니라 flush 이전에 cascade를 했기 때문입니다.
우선 JPQL을 호출하기 전에 child의 insert는 호출됐는데 왜 mother의 update는 호출이 되지 않은 건지 너무나 궁금했습니다.
를 쭉쭉 타고 들어가다보면 autoFlushIfRequired() 메서드를 호출하는 걸 볼 수 있습니다.")
1 | /** |
그리고 그 안에는 AutoFlushEvent를 발생시키고 있습니다.
DefaultAutoFlushEventListener의 onAutoFlush 메서드를 이벤트 리스너로 등록하고 있습니다.1
2
3
4
5
6
7
8
9
10
11
12public void onAutoFlush(AutoFlushEvent event) throws HibernateException {
final EventSource source = event.getSession();
final SessionEventListenerManager eventListenerManager = source.getEventListenerManager();
try {
eventListenerManager.partialFlushStart();
if ( flushMightBeNeeded( source ) ) {
// ...
}
// ...
}
}
onAutoFlush 메서드에서는 flush가 필요한지 확인하고 있는데

에는 현재 하나도 쿼리가 없는 상태입니다.")
1 | protected void flushEverythingToExecutions(FlushEvent event) throws HibernateException { |
flushEverythingToExecutions를 보면 prepareEntityFlushes, prepareCollectionFlushes를 통해 플러시 전처리를 하고,
flushEntities, flushCollections 메서드를 통해 실제로 플러시를 하는 것 같습니다.
이제 prepareEntityFlushes 메서드를 딥다이브 해봅시다.
 메서드 호출을 통해) 엔티티에 대해 영속성 전이(cascade)를 하고 있습니다.")
현재 영속성 컨텍스트에 엔티티는 Mother(#1) 엔티티 하나 뿐이고, flush 하기 전에 엔티티에 대해서 영속성 전이시키는 걸 볼 수 있습니다.

참고로 getCascadingAction()의 결과는 ACTION_PERSIST_ON_FLUSH입니다.




의 isEntityType() 메서드가 true이기 때문에 cascadeCollectionElements 메서드가 호출됩니다.")




의 persistOnFlush에서 PersistEvent를 만들고 있습니다.")


가 true라서 큐에 인서트 액션을 넣지 않고, 바로 executeInserts 메서드를 호출해서 쿼리를 실행하고 있습니다.")





에는 UnsafeObjectFieldAccessorImpl의 set 메서드를 호출합니다.")
에는 UnsafeQualifiedObjectFieldAccessorImple의 set 메서드를 호출합니다.")
 primitive long 타입인 경우에는 UnsafeQualifiedLongFieldAccessorImple의 set 메서드를 호출합니다.")
Mother는 왜 update 되지 않았는가?
이것도 내용이 길어서 3줄 요악 해보겠습니다.
- AbstractFlushingEventListener 클래스의 flushEntities 메서드에서는 flush 호출 이전에 영속성 컨텍스트에 있는 엔티티에 대해 Dirty Checking이 발생하고, 쿼리 지연 저장소(ActionQueue)에 EntityUpdateAction을 추가합니다.
- DefaultAutoFlushEventListener 클래스의 flushIsReallyNeeded 메서드에서는 하이버네이트의 기본 FlushMode가 ALWAYS가 아니고(하이버네이트 기본은 FlushMode.AUTO임), AutoFlushEvent의 querySpaces([family_register])가 쿼리 지연 저장소(ActionQueue)에 있는 액션(EntityUpdateAction)과 관련 없는 테이블(mother)이기 때문에 false를 반환합니다.
- 힘겹게 쿼리 지연 저장소에 다 밀어넣었건만 flushIsReallyNeeded가 false이면 결국 flush는 호출되지 않습니다.
결국 Mother의 변경내역은 쿼리 지연 저장소에 저장됐지만 현재 JPQL에서 사용하는 family_register와 상관 없는 테이블인 mother이므로 flush가 호출되지 않습니다.
이제 엔티티를 flush할 준비(prepareEntityFlushes 메서드)가 끝났으니 다음 부분(flushEntities 메서드)을 딥다이브 해봅시다.
 단계에서는 cascade를 수행하고, 아직 쿼리 지연 저장소는 비어있습니다.")

을 하고 있습니다.")

1 | protected final boolean isUpdateNecessary(FlushEntityEvent event) throws HibernateException { |
DefaultFlushEntityEventListener의 isUpdateNecessary 메서드에서 dirtyProperties 유무에 따라 업데이트가 필요한지 판단하고 있는데 하나가 있기 때문에 true를 반환합니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public void onFlushEntity(FlushEntityEvent event) throws HibernateException {
final Object entity = event.getEntity();
final EntityEntry entry = event.getEntityEntry();
final EventSource session = event.getSession();
final EntityPersister persister = entry.getPersister();
final Status status = entry.getStatus();
final Type[] types = persister.getPropertyTypes();
final boolean mightBeDirty = entry.requiresDirtyCheck( entity );
final Object[] values = getValues( entity, entry, mightBeDirty, session );
event.setPropertyValues( values );
//TODO: avoid this for non-new instances where mightBeDirty==false
boolean substitute = wrapCollections( session, persister, entity, entry.getId(), types, values );
if ( isUpdateNecessary( event, mightBeDirty ) ) {
substitute = scheduleUpdate( event ) || substitute;
}
isUpdateNecessary가 true이기 때문에 scheduleUpdate 메서드가 호출되는데 이름만 봐도 바로 지연 저장소에 저장할 거 같은 메서드네요.
에다가 EntityUpdateAction을 추가하고 있네요.")
하지만 여기까지 왔다고 해서 flush가 정말로 되는 건 아닙니다.1
2
3
4
5
6
7
8
9
10
11
12
13public void onAutoFlush(AutoFlushEvent event) throws HibernateException {
final EventSource source = event.getSession();
final SessionEventListenerManager eventListenerManager = source.getEventListenerManager();
try {
eventListenerManager.partialFlushStart();
if ( flushMightBeNeeded( source ) ) {
// Need to get the number of collection removals before flushing to executions
// (because flushing to executions can add collection removal actions to the action queue).
final ActionQueue actionQueue = source.getActionQueue();
final int oldSize = actionQueue.numberOfCollectionRemovals();
flushEverythingToExecutions( event );
if ( flushIsReallyNeeded( event, source ) ) {
flushMightBeNeeded에서 ‘flush가 필요할지도 몰라’ 정도까지만 판단을 하고, flushIsReallyNeeded에서 ‘정말로 flush가 필요한가?’에 대한 검토를 또 하고 있네요.
(지금까지 우리는 flushEverythingToExecutions에 대해 딥다이브를 마쳤습니다.)
와 관련이 있는지를 확인해보고 있네요.")
을 반복하는데 그 중에 현재 큐에 있는 액션은 Update(Mother 엔티티에 대한) 뿐입니다.")
해당 액션이 family_register 테이블과 관련이 있는지 확인하고 있습니다.
의 테이블(mother)과 이벤트의 querySpace의 테이블(family_regiser)와 관련이 있는지를 확인하고 있네요.")
관련이 없기 때문에 false를 반환합니다.
JPQL 호출 시 flush를 무조건 호출하는 줄 알았는데 쿼리 지연 저장소에 생긴 쿼리의 테이블과 관련이 있다는 사실도 참 신기하네요. (어찌보면 쿼리를 날릴 필요가 없으면 안 날리는 게 최적화 측면에서는 당연해보이긴 하네요.)
motherRepository.save(mother)는 왜 아무런 쿼리도 호출하지 않는가?
이것도 내용이 길어서 3줄 요악 해보겠습니다.
- mother가 새로운 엔티티는 아니기 때문에 entityManager.merge(mother)가 호출되고, Merge 이벤트를 발생시킵니다.
- Merge 이벤트의 핸들러인 DefaultMergeEventListener 클래스의 onMerge 메서드에서는 엔티티의 상태가 Persistent이므로 entityIsPersistent 메서드가 호출되는데 cascade는 이전(JPQL 호출 시)에 진작 끝냈기 때문에 아무런 쿼리가 호출되지 않습니다.
- 최상단 트랜잭션(obGyn.naturalDeliveryWith 메서드)이 끝나지 않아 commit을 호출하지 않았기 때문에 flush도 호출되지 않았습니다.

새로운 엔티티냐, 아니냐에 따라 persist vs merge 메서드를 호출하는데1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public boolean isNew(T entity) {
ID id = getId(entity);
Class<ID> idType = getIdType();
if (!idType.isPrimitive()) {
return id == null;
}
if (id instanceof Number) {
return ((Number) id).longValue() == 0L;
}
throw new IllegalArgumentException(String.format("Unsupported primitive id type %s!", idType));
}
AbstractEntityInformation 클래스의 isNew 메서드를 보면 primitive 타입이 아니면 null이거나 Number 타입이면 0인 경우에만 새로운 엔티티라고 취급하고 있습니다.
근데 Mother는 id에 값이 있기 때문에 새로운 엔티티가 아니라서 EntityManager의 merge 메서드가 호출됩니다.
의 merge 메서드가 호출되고 MergeEvent를 생성하고 있습니다.")
 상태이므로 entityIsPersistent 메서드가 호출됩니다.")
을 카피 뜨는 거라 크게 관련이 없는 코드입니다.")
의 트랜잭션이 전파된 거라 새로운 트랜잭션은 아니라서 실제 커밋이 수행되지는 않아 flush도 호출되지 않습니다.")
왜 부모 트랜잭션이 끝난 이후에 mother의 update 쿼리가 날아갔을까?
여기도 3줄 요약해보겠습니다.
- 트랜잭션이 모두 끝나고 커밋하기 이전에 flush를 해야하는지 FlushMode를 확인합니다.
- FlushMode가 MANUAL이 아니기 때문에 엔티티매니저에 대해 FlushEvent가 발생합니다.
- FlushEvent가 발생하면 DirtyChecking 및 쿼리 지연 저장소에 저장한 후에 flush가 이루어집니다.
motherRepository.save(mother)에서는 아무런 메서드가 날아가지 않고, 부모 트랜잭션(obGyn.naturalDeliveryWith 메서드)이 끝날 때 무슨 코드 때문에 쿼리를 호출하는 건지도 궁금해졌습니다.
1 | public void flushBeforeTransactionCompletion() { |
하이버네이트의 기본 FlushMode는 AUTO이기 때문에 doFlush가 true이고, managedFlush 메서드를 호출하게 됩니다.
의 doFlush를 호출하는데 이 때 FlushEvent를 발생시킵니다.")

FlushEvent의 이벤트 리스너 안에서 Managed Entity가 존재하므로 if 문 안을 보면, flushEverythingToExecutions을 호출하는데 이 때 Dirty Checking과 쿼리 지연 저장소에 저장이 이루어집니다.
그리고 performExecutions 안에서 실제 쿼리 지연 저장소에 있는 내용에 대해 flush가 호출됩니다.
motherRepository.save(mother)를 먼저 수행했을 때 child의 레퍼런스는 왜 바뀌었을까?
여기도 너무 길어서 4줄 요약해보자면
- mother가 새로운 엔티티는 아니기 때문에 entityManager.merge(mother)가 호출되고, mother 엔티티에 대해 Merge 이벤트를 발생시킵니다.
- Merge 이벤트의 핸들러인 DefaultMergeEventListener 클래스의 onMerge 메서드에서는 Managed Entity에 대해서 cascade가 발생하는데 child 엔티티에 대해서도 Merge 이벤트를 발생시킵니다.
- DefaultMergeEventListener 클래스의 onMerge 메서드에서는 Transient 상태인 child 엔티티에 대해서 카피본을 뜨고 카피에다가만 id를 할당한 후에 MergeContext 캐시에 entity를 key로, copy를 value로 할당하고 있습니다.
- mother 엔티티의 Merge 이벤트에서는 cascade가 전부 끝난 이후에 프로퍼티에 값 재할당이 일어나는데 이 때 children을 전부 비우고 copy로 채워넣으면서 레퍼런스가 바뀌게 됩니다.
1 |
|







의 merge 메서드를 호출하고 있습니다.")
의 merge 메서드에서 MergeEvent를 만들고 있습니다.")
여기가 핵심입니다.
이전에 JPQL 호출 시 AutoFlushEvent의 이벤트 리스너에서는 ACTION_PERSIST_ON_FLUSH CascadingActions의 cascade를 호출하면서 Child 엔티티에 대해 PersistEvent를 발생시켰는데,
motherRepository.save 호출 시 MergeEvent의 이벤트 리스너에서는 ACTION_MERGE인 CascadingActions의 cascade를 호출하면서 Child 엔티티에 대해 MergeEvent를 발생시키고 있습니다.
그럼 PersistEvent와 MergeEvent의 차이점을 알아봅시다.
 상태이기 때문에 entityIsTransient 메서드가 호출됩니다.")
또 결정적 차이가 여기서 나옵니다.
PersistEvent의 이벤트 리스너인 DefaultPersistEventListener 클래스의 onPersist 메서드에서 호출하는 DefaultPersistEventListener 클래스의 entityIsTransient 메서드에서는 entity에 대해 카피를 뜬 적이 없습니다.
하지만 MergeEvent의 이벤트 리스너인 DefaultMergeEventListener 클래스의 onMerge 메서드에서 호출하는 DefaultMergeEventListener 클래스의 entityIsTransient 메서드에서는 entity에 대해 카피를 뜨고 있습니다.
카피 뜰 때 default constructor가 없으면 아마도 org.hibernate.InstantiationException: No default constructor for entity 요런 예외를 던지지 않을까 싶네요.
기본 생성자를 호출했기 때문에 아직 값은 카피되지 않고 객체 생성까지만 된 상태입니다.
그리고 copyCache라는 MergeContext에 entity를 key로, copy를 value로 해서 넣고 있습니다.
그리고 saveTransientEntity 메서드에서 실질적인 insert가 이루어지는데 entity를 넘기는 게 아니라 copy를 넘기고 있습니다.



이렇게 copy를 뜨고, copy에만 id를 할당하고, collection을 비운 후 copy로 채우기 때문에 외부 변수는 여전히 id가 null인 상태로 남게 됩니다.
여담으로 child가 Transient 상태이기 때문에 카피를 뜨고 카피로 레퍼런스를 바꾸고 했는데, 이미 Persistent 상태인 child였다면 카피를 뜨지 않아 레퍼런스를 바꾸지 않습니다.
Persist vs Merge
이제 진짜 하고 싶었던 핵심인 엔티티 매니저의 persist와 merge 메서드에 대해 이야기 해보겠습니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public interface EntityManager {
/**
* Make an instance managed and persistent.
* @param entity entity instance
* @throws EntityExistsException if the entity already exists.
* (If the entity already exists, the <code>EntityExistsException</code> may
* be thrown when the persist operation is invoked, or the
* <code>EntityExistsException</code> or another <code>PersistenceException</code> may be
* thrown at flush or commit time.)
* @throws IllegalArgumentException if the instance is not an
* entity
* @throws TransactionRequiredException if there is no transaction when
* invoked on a container-managed entity manager of that is of type
* <code>PersistenceContextType.TRANSACTION</code>
*/
public void persist(Object entity);
/**
* Merge the state of the given entity into the
* current persistence context.
* @param entity entity instance
* @return the managed instance that the state was merged to
* @throws IllegalArgumentException if instance is not an
* entity or is a removed entity
* @throws TransactionRequiredException if there is no transaction when
* invoked on a container-managed entity manager of that is of type
* <code>PersistenceContextType.TRANSACTION</code>
*/
public <T> T merge(T entity);
// ...
}
별 건 없고, persist는 return 타입이 없고, merge는 있는 게 가장 큰 차이입니다.
어디서 봤는데 return 타입이 없으면 원본 객체를 수정하고, return type이 있으면 새로운 객체를 반환하는 게 뭐 뭘 분리해서 좋은 패턴이다~
라는 걸 본 거 같은데 아시는 분 있으면 댓글 남겨주시면 감사하겠습니다.
여튼 위에서 말했듯 그런 패턴을 지킨 걸로 보입니다.
persists는 return 타입이 없는데 id는 할당해야하니 당연히 새로운 객체를 만들 수는 없고 원본 객체를 수정할테고,
merge는 return 타입이 있는 걸로 보아 원본 객체는 수정하지 않고, id가 할당된 새 객체를 반환하는 걸로 보입니다.
persist와 merge에 대해 이해하면 위에서 있었던 PersistEvent와 MergeEvent가 왜 그렇게 동작했는지 이해할 수 있게 됩니다.
JPQL 호출 시 cascade가 이루어질 때는 PersistEvent가 발생하기 때문에 persist 메서드의 특성을 생각해보면 원본 객체에 id가 할당됐던 것이 당연한 게 됩니다.
그리고 save 호출 시 cascade가 이루어질 때는 새로운 엔티티가 아니라서 MergeEvent가 발생했기 때문에 merge 메서드의 특성을 생각해보면 새로운 객체를 반환하고, 레퍼런스도 바꿔치는 게 당연한 게 됩니다.
그럼 persist와 merge에 대한 간단한 예제를 보시면 이해하시는 데 더 도움이 될 것 같습니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
fun `새로운 엔티티라면 persist가 호출되면서 원본 엔티티를 반환하고, 새로운 엔티티가 아니면 merge가 호출되면서 새로운 엔티티 객체를 반환한다`() {
val mother = Mother()
val persistedMother = motherRepository.save(mother)
persistedMother shouldBeSameInstanceAs mother
val newMother = Mother(2L)
val mergedNewMother = motherRepository.save(newMother)
mergedNewMother.id shouldBe 2L
mergedNewMother shouldNotBeSameInstanceAs newMother
val mergedMergedNewMother = motherRepository.save(mergedNewMother)
mergedMergedNewMother.id shouldBe 2L
mergedMergedNewMother shouldNotBeSameInstanceAs mergedNewMother
mergedMergedNewMother shouldNotBeSameInstanceAs newMother
}
푸념
단순히 save 메서드의 위치를 바꿨다고 해서 이렇게까지 동작이 달라질 줄은 몰랐습니다.
복잡한 연관관계(CascadeAction 등등)와 JPQL이 어느 타이밍에 호출되는데 엔티티는 현재 어떤 상태인지 등등을 고려해가면서 코드를 짜야하니 예측성이 너무 떨어지는 것 같습니다.
엔티티를 객체-테이블 매핑 이상의 역할인 도메인(비즈니스 로직을 담은) 객체로 사용하고, 역할에 맞게 객체를 덜 쪼갰기 때문에 요런 문제가 발생하긴 했지만…
이제 JPA가 그렇게 좋은지 모르겠네요… 예측성이 너무 떨어지고, 알아야할 게 너무 많은 거 같습니다.