(Troubleshooting) Thread Dump 분석 도전기

사건의 시작

갑자기 Nginx가 Down 됐다는 알림이 와서 해당 서버로 접속해보니 Nginx 서비스는 정상적으로 떠있고…
curl도 때려보고, 브라우저에서 직접 URL로 접속해봤을 때 문제가 없었다.1
2
3
4
5
6
7
8
9
10# blackbox exporter configuration
modules:
http_health:
prober: http
timeout: 5s
http:
method: GET
valid_status_codes: [200]
preferred_ip_protocol: "ip4"
ip_protocol_fallback: false
80포트에 대해서 http 요청을 보냈을 때 5초 이내에 200 OK가 안 오면 알람을 발생시키게 했는데 내가 테스트 해 본 바로는 아무런 문제도 없었다.
(일단 5초라는 관대한 시간으로 걸어놓은 것도 문제였고, 내가 간단히 메인 페이지만 몇 번 들락날락 해본 것도 문제였다.)
따라서 나는 Alert Manager가 오작동하나 보다... 역시 내가 이 쪽 경험이 부족하다보니 뭔가 잘못 셋팅했나 보다.하며 대수롭지 않게 넘겼다.
불행의 시작

우선 열심히 구축해놓은 모니터링 시스템을 굴릴 수 없으니 EC2 인스턴스 및 JVM 메모리에 대한 지표를 살펴보았다.
우선 인스턴스의 CPU나 메모리는 문제가 없었고 JVM 메모리나 GC 쪽에도 문제가 없었다.



나는 쓰레드 쪽에 문제가 있으니 우선 쓰레드 덤프부터 뜨고 봐야하나? 이 생각이었는데 저 지표를 보자마자 저런 생각이 떠오른다는 건 역시 경험은 무시할 수가 없는 것 같다.

Troubleshooting
우선 DB 쪽에 장애가 서버까지 전파된 걸 확인했으니 서버 쪽에서 어떤 쿼리를 수행하길래 저런 에러가 나오는지 봐야했다.
쓰레드 쪽에 문제가 있다고 판단했으니 우선 jstack으로 쓰레드 덤프를 뜨고 별도의 툴을 깔지 않고 온라인(fastThread)에서 쓰레드 덤프를 분석해봤다.

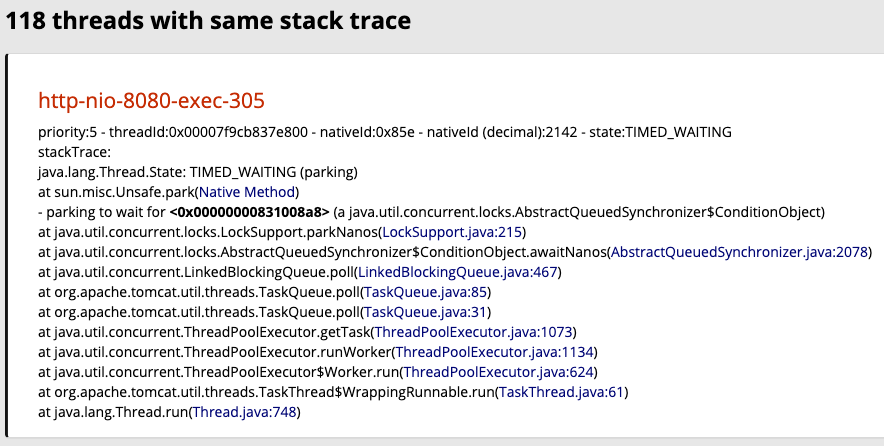
나는 뭔가 어플리케이션 코드가 스택 트레이스에 찍혀있길 기대했지만 그런 건 없었다.
일단 쓰레드 네임을 보아하니 http 요청에 의한 것으로 판단되니 Nginx의 Access Log를 뒤져보면 뭔가 나오지 않을까 싶었다.

파라미터에도 ALL 하나만 들어가있는 걸 보면 뭔가 전체 조회를 하는 구린 냄새가 나는 코드 같다.
눈여겨 볼 점은 처음 발생한 시점이다.
11시 20분에 저렇게 느린 요청들이 발생하기 시작했는데, 내가 알람을 받은 건 23분부터 받기 시작했다.
아마 5초라는 관대한 시간을 줬기 때문에 더 알람을 늦게 받게된 게 아닌가 싶다.

이제는 유저가 못참고 페이지를 이탈해서 HTTP Status Code 499도 나왔다.
동일한 API에서 계속해서 10초 이상이 걸리고, 점점 느려지는 걸 보니 해당 API의 문제가 맞다고 80% 정도는 확신을 했다.
실제로 해당 코드를 보니 페이징 처리나 조건문이 좀 부실했었고, 쿼리를 손 본 후에야 문제를 해결할 수 있었다.
오늘의 교훈

피…피카츄!!
Alert Manger가 알림을 줬을 때 난 무시를 했다.
아니 무시한 건 아니지만 아주 간단하게만 테스트했다.
기계는 사람보다 정확하니 무시하지 말고 좀 더 면밀히 관찰하고 얼른 팀 내에 공유를 해야 앞으로 이런 사태가 발생하지 않을 것 같다.