자바의 Virtual Thread가 나와도 코틀린의 코루틴은 여전히 살아남을까?
Java Virtual Threads 훑어보기에서 Virtual Thread에 대해 대충 훑어봤었고, 2023/09/19에 나오는 JDK21(심지어 LTS)에서 Virtual Threads (JEP 444)가 정식으로 출시된다는 소식을 들었다.
그러다보니 코틀린의 코루틴의 소식이 궁금했다.
출처: https://www.youtube.com/live/QxxG66eQoTc?feature=share&t=3652
많은 사람들이 Virtual Thread가 코루틴과 같은 역할을 할 수 있을지 궁금해하는 것 같았고, 나 또한 코루틴을 잘 모르는 입장에서 ‘결국 코루틴은 사장되는 게 아닐까?’란 생각이 들었다.
그러던 중 Coroutines and Loom behind the scenes by Roman Elizarov라는 영상을 보게 되어서 이해한 내용을 겸사겸사 정리해보았다. (나중에 회사에서 Virtual Thread 적용 할 때 고민해야할 부분도 함께 적어두기 위해서도 있지만…)
우선 해당 포스트에서는 Virtual Thread에 대한 기본적인 내용들은 알고 있다는 전제 하에 작성했다.
Java Virtual Threads 훑어보기
Java의 Virtual Threads는 JDK 19에 Preview Features로 추가되었다.
프로젝트 룸(Loom)에서 개발한 기능으로 알고있는데 사실 큰 관심도 없던(뭐하는 지도 모르던) 프로젝트였고, JDK 19가 LTS도 아니기 때문에 회사에서 바로 써볼 수도 없기에 JDK 19는 큰 관심도 가지고 있지 않았다.
하지만 최근 스프링 블로그에서 Embracing Virtual Threads 라는 포스트가 올라온 걸 보고 살짝 관심 가지게 되었다.
Spring Web MVC와 같이 전형적인 1 Request per 1 Thread 모델의 한계(쓰레드 자체가 많은 메모리를 소비하고, 컨텍스트 스위칭에 따른 불필요한 시간 소요 등등)를 극복하기 위해
Spring Webflux(가 의존하는 Netty)에서는 코어 갯수 * 2개만의 쓰레드를 만듦으로 인해 그 한계를 극복하였지만 하나의 요청을 하나의 쓰레드가 온전히 처리하는 것이 아니기 때문에 스택트레이스를 봐도 파편화된 정보가 남아 트러블 슈팅에 문제가 있었고,
Mono나 Flux와 같은 Publisher 타입으로 값을 감싸야 하기 때문에 코드가 매우 보기 힘들고, 어디서 쓰레드를 블락하는 코드를 호출하는 건 아닌지 항상 불안에 떨었어야했다.
그러다보니 Webflux가 더 고성능을 보장하더라도 유지보수하기가 힘들고 러닝커브 또한 존재하기 때문에 어지간한 경우가 아니면 Web MVC로 프로젝트를 만들었다.
사실 프로덕션에서 RDBMS를 안 쓰는 곳이 거의 없는데 R2DBC를 사용하기에는 너무 불안정해 보이기도 했고, 그리고 TPS가 안 나오면 대부분 스케일 아웃하는 형태로 해결을 많이 했다.
서버보다는 사람이 가장 비싼 자원이라고 생각되기에 유지보수 측면으로만 생각하다보니 Webflux는 거의 사용한 적이 없는 것 같다.
결정적으로 Web MVC(Spring Boot를 사용한다면 톰캣의 최대 쓰레드인 200개)만으로도 부족함이 없는 서비스도 많았고, 단일 서버가 아닌 이중화 등등으로 인해 서버가 다중으로 뜨기에 Webflux를 써야할 만큼의 처리를 단일서버에서 하지 않는 경우가 대다수였다.
그럼에도 불구하고 Virtual Threads는 어떠한 문제를 해결해주는 것인지, Spring과 함께 사용하면 어떤 시너지를 낼 수 있을지 궁금해서 살짝만 훑어보았다.
Platform Threads
히카리 CP에서 다양한 시간 설정해보기
Spring Boot 2에서 제공하는 RDB 관련 의존성을 추가하면 DB의 커넥션 풀을 관리하기 위해 기본적으로 사용하는 HikariCP는 시간 관련해서 다양한 설정들이 있다.
하지만 그냥 설명하는 것만 봐서는 무슨 내용인지 헷갈리는 설명들이 있어서 요번에 프로젝트에 도입된 설정들을 포함해 몇가지 정리를 해보았다.
maxLifeTime
⏳maxLifetime
This property controls the maximum lifetime of a connection in the pool.
An in-use connection will never be retired, only when it is closed will it then be removed.
On a connection-by-connection basis, minor negative attenuation is applied to avoid mass-extinction in the pool.
We strongly recommend setting this value, and it should be several seconds shorter than any database or infrastructure imposed connection time limit.
A value of 0 indicates no maximum lifetime (infinite lifetime), subject of course to the idleTimeout setting.
The minimum allowed value is 30000ms (30 seconds). Default: 1800000 (30 minutes)
커넥션 풀에서 idle 커넥션이 최대 얼마동안 생존할 수 있냐는 설정이다. (단위는 ms, 기본값은 30분, 최소값은 30초, 0으로 설정하면 무제한)
반환될 때마다 idle time은 다시 0으로 초기화 될테니 트래픽이 많이 들어와서 커넥션이 계속 사용되는 서비스라면 이 설정에 의해 커넥션이 종료될 일은 적을 것이다.
sequenceDiagram
autonumber
participant Server
participant Hikari as HikariCP (maxLifeTime: 30000ms(30s))
participant C1 as Connection 1 (current idle time: 20s)
participant C2 as Connection 2 (current idle time: 15s)
Server ->> Hikari: getConnection()
Hikari ->> C1: getConnection()
C1 ->> Hikari: Connection 1
Hikari ->> Server: Connection 1
Server ->> Hikari: releaseConnection(Connection 1)
Hikari ->> C1: release (reset idle time to 0s)TDD는 Design Acitivity이다.
1~2년 전 쯤 존경하는 개발자 분과 함께 A Brief History of Mock Objects라는 아티클을 함께 본 적이 있다.
개인적으로 이렇게 특정 개념의 근본이 된다던지, 해당 분야의 대가들이 쓴 아티클들을 함께 보는 것으로 인해 굉장히 많은 인사이트들이 생겼던 것 같다.
객체의 테스트 때문에 추가했던 getter로부터의 해방을 위해 고민하던 것으로 시작한 게 Mock의 탄생이라는 사실을 알게 되었을 때는 정말 위대한 탄생이라고 생각했다.
그리고 문득 시간이 지나 해당 아티클을 다시 보고 싶어졌다. (물론 해당 아티클은 테스트 주도 개발로 배우는 객체 지향 설계와 실천 책의 후기에 한글로 적혀있다.)
아티클을 보던 중에 후반 부분에 Mock과 관련해서 Mock Roles, not Objects라는 논문까지 썼다는 걸 보고 해당 논문까지 봐야 Mock에 대해 정확한 이해를 할 수 있을 것 같아 해당 논문을 보게 되었다.
그리고 목의 역사와 마찬가지로 해당 논문도 너무나 감명이 깊어 한 번 느낀점이나 내용을 정리해보고 싶었다.
Writing tests is a design activity
먼저 TDD(Test Driven Development)에는 크게 두 가지 관점이 존재할 것 같다.
첫 번째로 “검증”이다.
코드들이 의도대로 동작하는지, 버그는 없는지 검증하는 것이다.
이를 통해 프로덕션에 코드를 내보내도 된다는 자신감이 올라가고, 리팩토링을 하거나 신규 기능을 추가하더라도 코드의 동작은 변하지 않았음에 확신을 가질 수 있다.
(Tomcat) ClientAbortException은 왜 발생할까? (Part 2)
서버에서 아주 가끔가다가 ClientAbortException(java.io.IOExceiption: Broken pipe)이 발생해서 어떨 때 발생하는지 딥다이브 해봄.

적다보니 글이 길어져 글을 나누었는데 해당 글을 읽기 전에 (Tomcat) ClientAbortException은 왜 발생할까? (Part 1)을 먼저 보는 것을 추천함.
https://tomcat.apache.org/tomcat-9.0-doc/api/org/apache/catalina/connector/ClientAbortException.html
(Tomcat) ClientAbortException은 왜 발생할까? (Part 1)
서버에서 아주 가끔가다가 ClientAbortException(java.io.IOExceiption: Broken pipe)이 발생해서 어떨 때 발생하는지 딥다이브 해봄.

적다보니 글이 길어져 글을 나누었는데 해당 글을 읽고 난 후에 (Tomcat) ClientAbortException은 왜 발생할까? (Part 2)를 마저 보는 것을 추천함.
https://tomcat.apache.org/tomcat-9.0-doc/api/org/apache/catalina/connector/ClientAbortException.html
(Gradle) 테스트 의존성 관리하기 (feat. java-test-fixtures 플러그인)
들어가기에 앞서
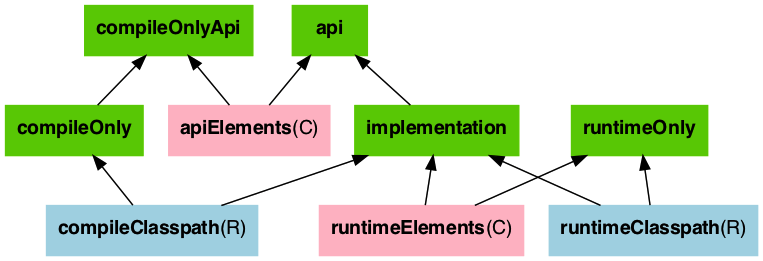
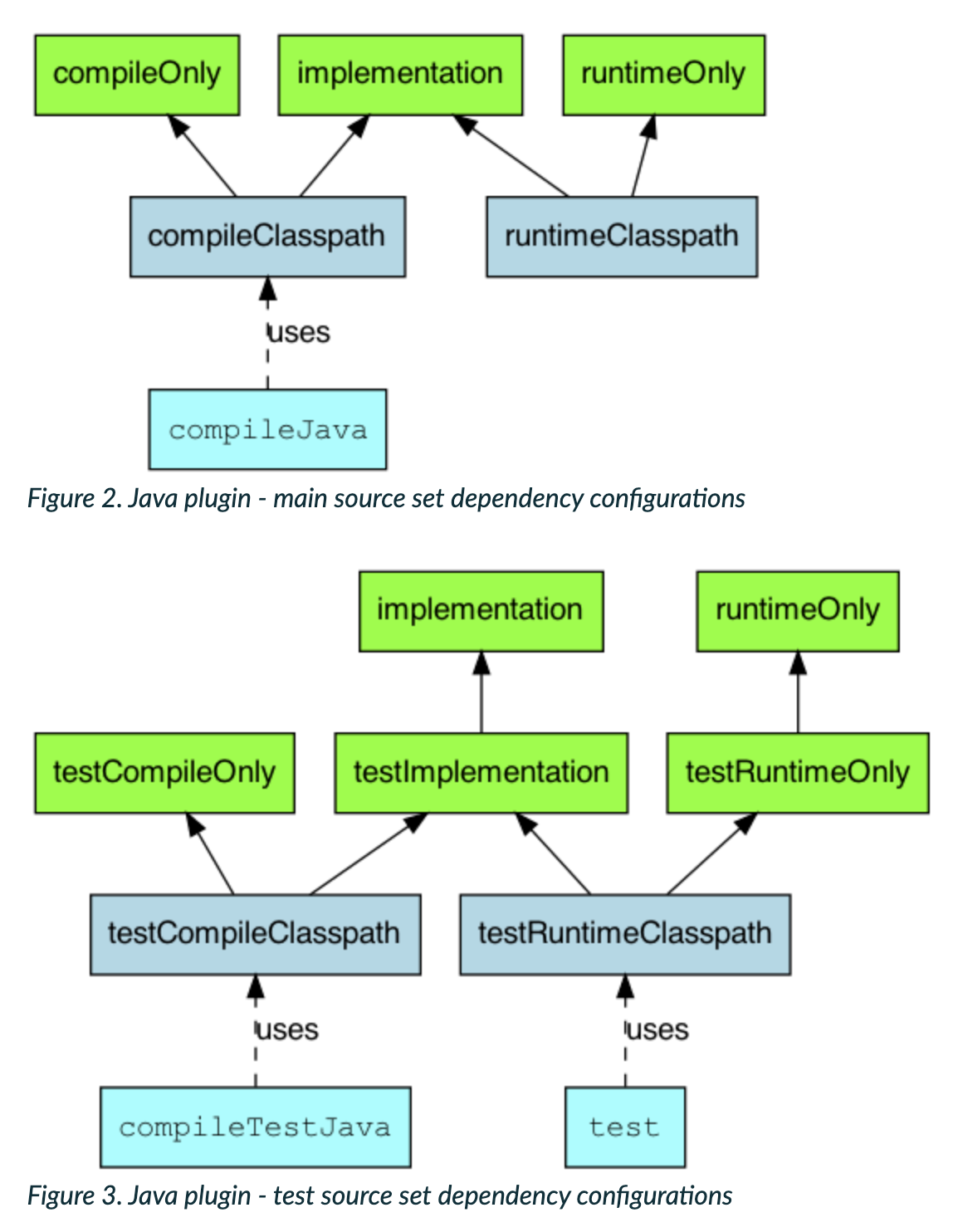
(Gradle) implementation vs api에서는 compile/runtime 의존성을 관리하는 방법에 대해 정리했다.
하지만 이는 실제 src/main 경로에 대해서만 의존성을 관리하는 것이지 src/test 경로에서 사용하는 테스트 의존성(testCompileClasspath, testRuntimeClasspath)에 대해서는 딥하게 다루지 않았다.
테스트도 관리해야할 대상이고 하나의 소프트웨어라는 관점에서 테스트의 의존성 조차도 신경을 써줘야한다.
testImplementation